Comments
The Rick Astley of Timeouts: maxTimeMS
tl;dr: Use maxTimeMS instead of client-side socket timeouts.
Some time ago, a MongoDB user opened PHP-1164 to report that connections had started to pile up on their server due to some long-running queries. The user was particularly concerned because the connection count had greatly exceeded the number of PHP workers on their app server(s).
Unlike most of our multi-threaded drivers, the single-threaded PHP driver uses persistent connections instead of pooling. You should generally expect each worker to keep a single connection per MongoDB endpoint (i.e. host, port, and auth combination) and reuse that socket between requests. For instance, an application that always connects to a three-node replica set would maintain three sockets per worker (one to each node). When the number of connections in mongostat starts to exceed your worker pool, that warrants some investigation.
Thankfully, the user was able to attach a small script that reproduced his problem:
MongoCursor::$timeout = 100;
$mc = new MongoClient();
$coll = $mc->test->php1164;
$cursor = $coll->find([
'profile.name'=> new MongoRegex('/^Edmunds/i'),
]);
var_dump(iterator_to_array($cursor));
This is pretty straightforward: we connect, execute a (hopefully) indexed query
using an anchored regex pattern, and finally iterate through the cursor and
dump our results. Apart from using the deprecated MongoCursor::$timeout
property instead of MongoCursor::timeout() or the
socketTimeoutMS connection option, it was fairly innocuous.
When benchmarking the script with 10 concurrent requests via ab, they found
active connections on the server climb to 1000+. netstat reported that the
majority of sockets local to the server were lingering in the CLOSE_WAIT
state. From the driver’s perspective, any sockets listed were reported as
FIN_WAIT or TIME_WAIT. This meant that the driver had closed its side of
the connection but we were still waiting for the server to acknowledge that.
The following state diagram1 helps put this into perspective:
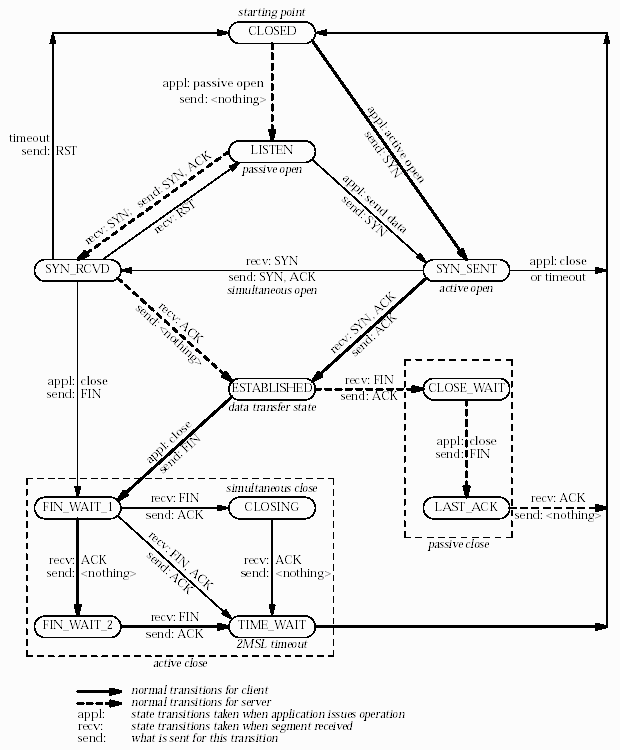
Without access to the user’s data files, I had to resort to other means of
reproducing the problem locally. I immediately thought of the $where
operator, which allows us to execute arbitrary JavaScript during query
evaluation2. Querying a non-empty collection with {"$where": "sleep(1000)"}
allows us to delay the match evaluation for each document by one second.
Combined with a 100 millisecond client-side timeout, we could simulate the
original issue and force the driver to abandon connections and queries that were
still executing on the server. The following script does just that:
$mc = new MongoClient(null, ['socketTimeoutMS' => 100]);
$coll = $mc->test->php1164;
$cursor = $coll->find([
'$where' => 'sleep(1000) || true',
]);
var_dump(iterator_to_array($cursor));
Before benchmarking, I tweaked my FPM pool configuration to allow the number of web workers to scale up to 1000. I usually have a static pool of two workers on my development machine, but we were going to need quite a bit more than that for this test:
pm = dynamic
pm.max_children = 1000
pm.min_spare_servers = 5
pm.max_spare_servers = 50
pm.start_servers = 5
With FPM restarted and the PHP script deployed to a virtual host, I kicked off a hundred thousand requests (500 at a time):
ab -r -n 100000 -c 500 http://php1164.local/
When running this test against MongoDB 2.6, I had mixed luck watching the server
load with mongostat. Execution of the serverStatus command it uses was
delayed by our blast of $where queries, which left gaps in the poll intervals.
For the record, MongoDB 3.0 did a much better job of reporting its stats under
heavy load. Here’s a snippet of the output during our test on 2.6:
query command qr|qw ar|aw netIn netOut conn time
*0 1|0 0|0 0|0 62b 3k 1 16:08:47
56 169|0 0|0 56|0 10k 57k 57 16:08:48
43 121|0 10|1 91|0 7k 42k 93 16:08:52
926 2380|0 1|1 798|0 151k 772k 799 16:09:07
1788 658|0 0|1 216|0 99k 269k 221 16:09:11
418 1|0 0|0 0|0 16k 18k 1 16:09:12
The gaps between poll intervals made it impossible to see the true query and
connection load on the server; however, tailing the server logs provided a more
accurate look at our connection load. Open connections on the server reached a
peak of 969 before the first queries finished executing and connections began to
close. Bumping the sleep() delay in our $where criteria up to 10 seconds
resulted in a peak of 2305 connections before the load began to subside.
While using $where for this test was a bit contrived, it did succinctly demonstrate the problem with client-side socket timeouts. Having the driver abruptly close sockets for long-running operations can inadvertently cause of DoS attack against your database server given a high enough request load.
- Sockets, file descriptors, and threads are limited resources. In this test, we were letting connections (i.e. threads with sockets) accumulate on the server as it needlessly prepares a response the driver will never read!
- Creating connections has overhead. Closing a socket on a long-running query prevents the driver from persisting that connection for the worker to re-use in a subsequent request.
Client-side timeouts certainly have their uses in allowing an application to remain responsive despite network latency or connectivity issues, but they are not a general tool for curtailing long-running operations. Thankfully, MongoDB 2.6 introduced the maxTimeMS query and command option expressly for that purpose.
Let’s see how replacing socketTimeoutMS with a call to
MongoCursor::maxTimeMS() can eliminate the DoS side-effect
of our original script.
$mc = new MongoClient;
$coll = $mc->test->php1164;
$cursor = $coll->find([
'$where' => 'sleep(1000) || true',
]);
$cursor->maxTimeMS(100);
var_dump(iterator_to_array($cursor));
This script relies on the driver’s default socket timeouts but trusts the server to gracefully abort the query on its own after 100 milliseconds of execution time (think CPU time vs. wall time). In contrast to our previous test, the driver will actually read a response from the server (albeit an error message) and keep the connection open for the next request. From the developer’s perspective, the only difference should be that a MongoExecutionTimeoutException will be thrown instead of a MongoCursorTimeoutException.
Running the revised script yields the following, abridged output from mongostat:
query command qr|qw ar|aw netIn netOut conn time
*0 1|0 0|0 0|0 79b 10k 51 17:23:06
97 104|0 0|0 51|0 6k 24k 52 17:23:07
107 7|0 0|0 53|0 6k 17k 54 17:23:08
76 13|0 0|0 57|0 6k 19k 58 17:23:09
74 17|0 0|0 62|0 7k 21k 63 17:23:10
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
315 64|0 0|0 270|0 32k 44k 288 17:23:55
328 82|0 0|0 277|0 34k 45k 293 17:23:56
316 116|0 0|0 281|0 37k 48k 298 17:23:57
345 87|0 0|0 286|0 37k 48k 303 17:23:58
404 91|0 0|0 307|0 38k 50k 308 17:23:59
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
13 16|0 0|0 275|0 1k 16k 498 17:24:38
879 308|0 0|0 298|0 75k 94k 503 17:24:39
15 12|0 0|0 294|0 2k 15k 506 17:24:40
433 91|0 0|0 398|0 18k 28k 506 17:24:41
457 294|0 0|0 297|0 64k 74k 506 17:24:42
We can see connections slowly ramp up to about 500, which is consistent with our
concurrency level. The initial connection count of 51 is also consistent with
pm.max_spare_servers from our FPM configuration, as the log was captured on a
subsequenty run after FPM had scaled down to an idle state.
In addition to the cursor method we used above, which sets the $maxTimeMS
meta operator on the query, most commands support a maxTimeMS option (support
for write commands is forthcoming in SERVER-13622). If you’re using
MongoDB::command(), the maxTimeMS option goes directly on the
command document itself, instead of in the array you might have previously used
to specify socketTimeoutMS. Other command helper methods are documented
accordingly.
While this won’t match the blazing performance of our DoS attack, it uses server and driver resources much more responsibly. This is doubly important given the PHP driver’s lack of connection pooling. Our persistent connection model means that the expected connection load for a single mongod comes down to:
web servers × worker pool size × mongod connections
Workers (i.e. driver instances) will typically require a single mongod connection. Multiple connections could be required if different sets of auth credentials are involved, but the number should still be predictable. But the equation breaks down when workers can consume more than their fair share of server resources, which is made all too easy with hasty socket timeouts. At scale, that can lead to a domino effect of abandoned connections. That said, maxTimeMS is the Rick Astley of timeouts—at least as far as sockets are concerned.
Never gonna give you up ♫
Never gonna let you down ♬
Never gonnaSO_RCVTIMEOand desert you ♫
-
$where should be used sparingly. It is best used in conjunction with other, selective query criteria, which can take advantage of an index and limit the number of JavaScript executions required. Including it in a collection scan (as we do here) is generally a bad idea unless you know what you’re doing. ↩